Feng Gao

Feng Gao received his Ph.D. from UCLA in 2022 co-advised by Ying Nian Wu and Mark Handcock. From 2017 to 2021, he was advised by Song-Chun Zhu.
He is currenty a Research Scientist at ByteDance. Specifically, he is
- Working on
Multimodal Foundation Models - 🔬 Actively research on
At ByteDance, he works on LLM post-training, building Multimodal LLM agents.
Before that, he was a researcher at Amazon, and he
- 🐶 Built
Rufus[News1], [News2], Amazon’s LLM-powered Shopping Assistant. - 🚀 Launch multimodal Rufus (
Rufus-MM).- Full-stack M-LLM development: data, pre-training, post-training, evaluation.
Feel free to contact me: fenggao [dot] pub [at] gmail [dot] com.
news
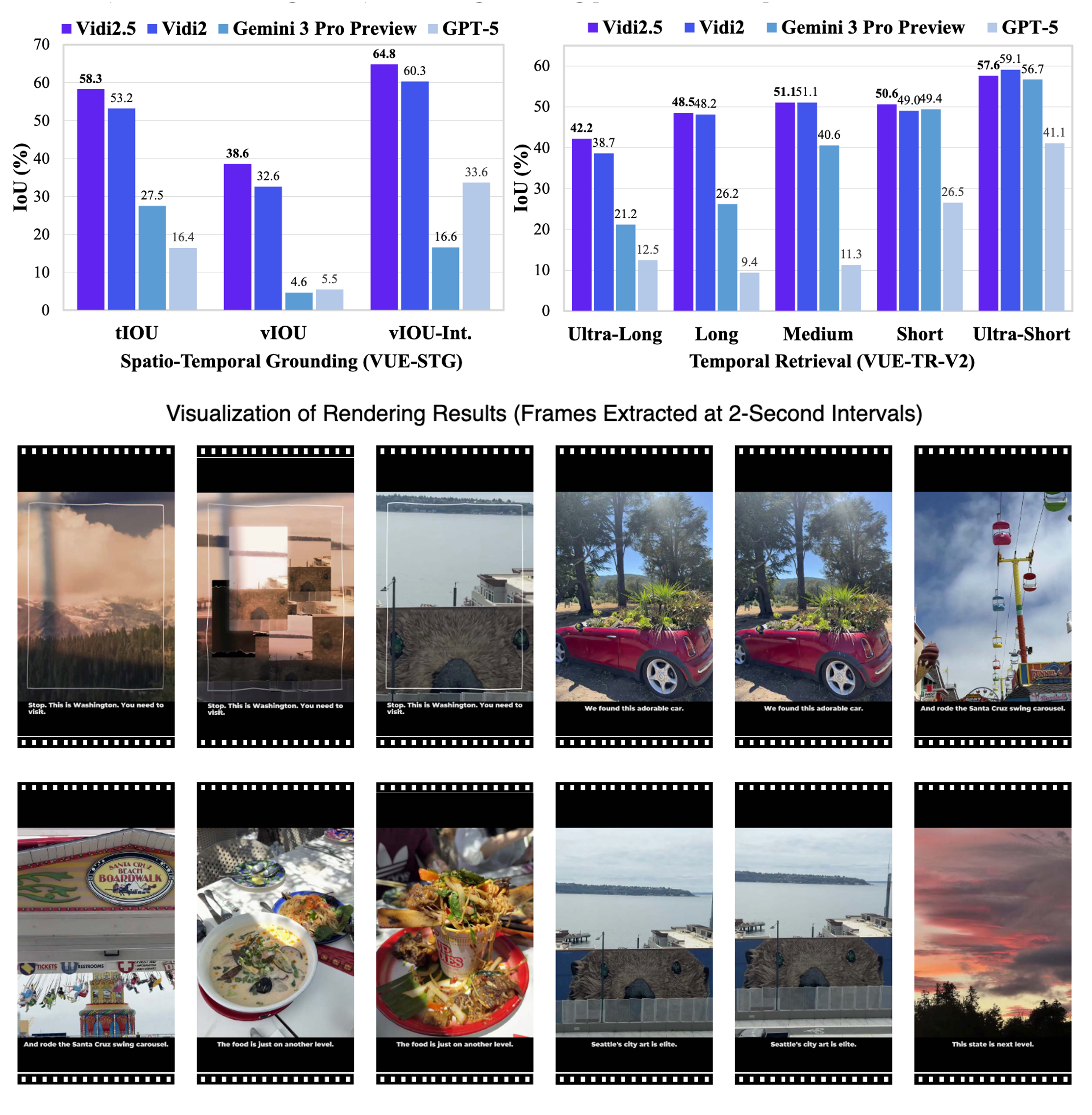
| Jan 20, 2026 | Model and technical report released. Multimodal LLMs for video understanding: ViDi2.5🔍 video editing/creation: ViDi-Edit 🎬. [demo] [paper] |
|---|---|
| Feb 26, 2025 | One paper about Relightable 3D Generation 🪑 [paper] [demo] is accepted to CVPR2025. |
| Feb 25, 2025 | One paper about efficient video-LLM 🎞️ [paper] is accepted to CVPR2025. |
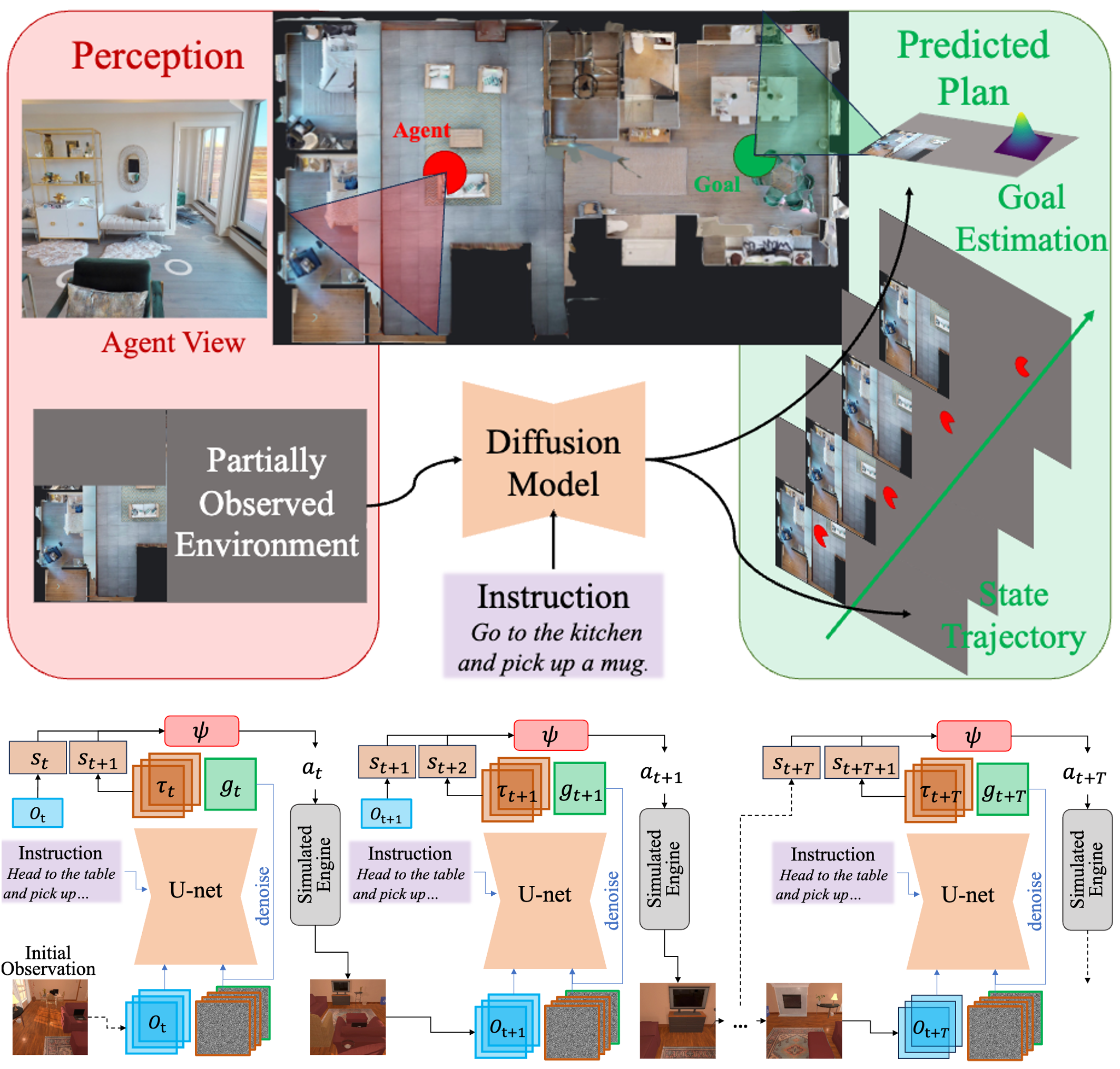
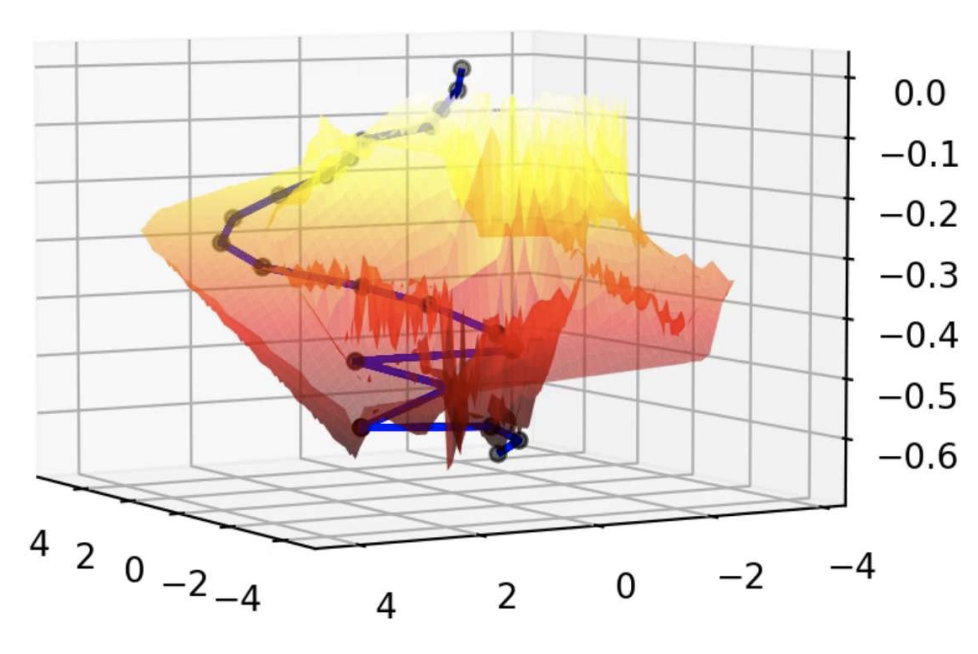
| Oct 14, 2024 | Our work about Embodied AI, Planning as In-Painting |
| Sep 25, 2024 | Two paper accepted to NeurIPS2024. They are about physically constrained Text-to-3D 🤸🏻♀️ [paper] [demo] and flow matching generative model [paper]. |
selected publications
- CVPR